Colibri Collection
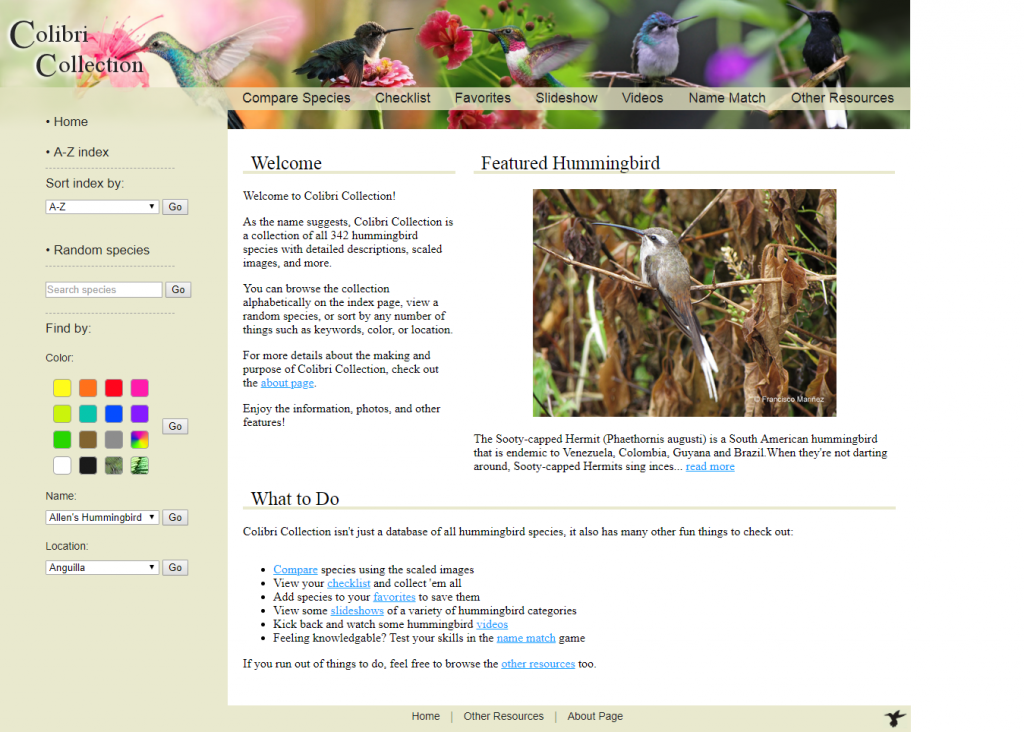
Colibri Collection is a wiki site built with:
- Portable Python
- Jinja
- Google App Engine
- Javascript/jQuery
- HTML/CSS
What made it a unique project is that it was designed to run off a USB thumb drive rather than be hosted online. This was mainly for a personal challenge and since it was developed solely for one fan group’s usage.
Another unusual aspect of the project was the implementation of photo scaling to fixed sizes no matter the screen size or resolution. This was done to give accurate, life-sized photos of the hummingbirds across any user’s device. It was accomplished through a database of hummingbird sizes in inches and a scaling function that automatically adjusted this size to pixels once the user’s resolution was known.
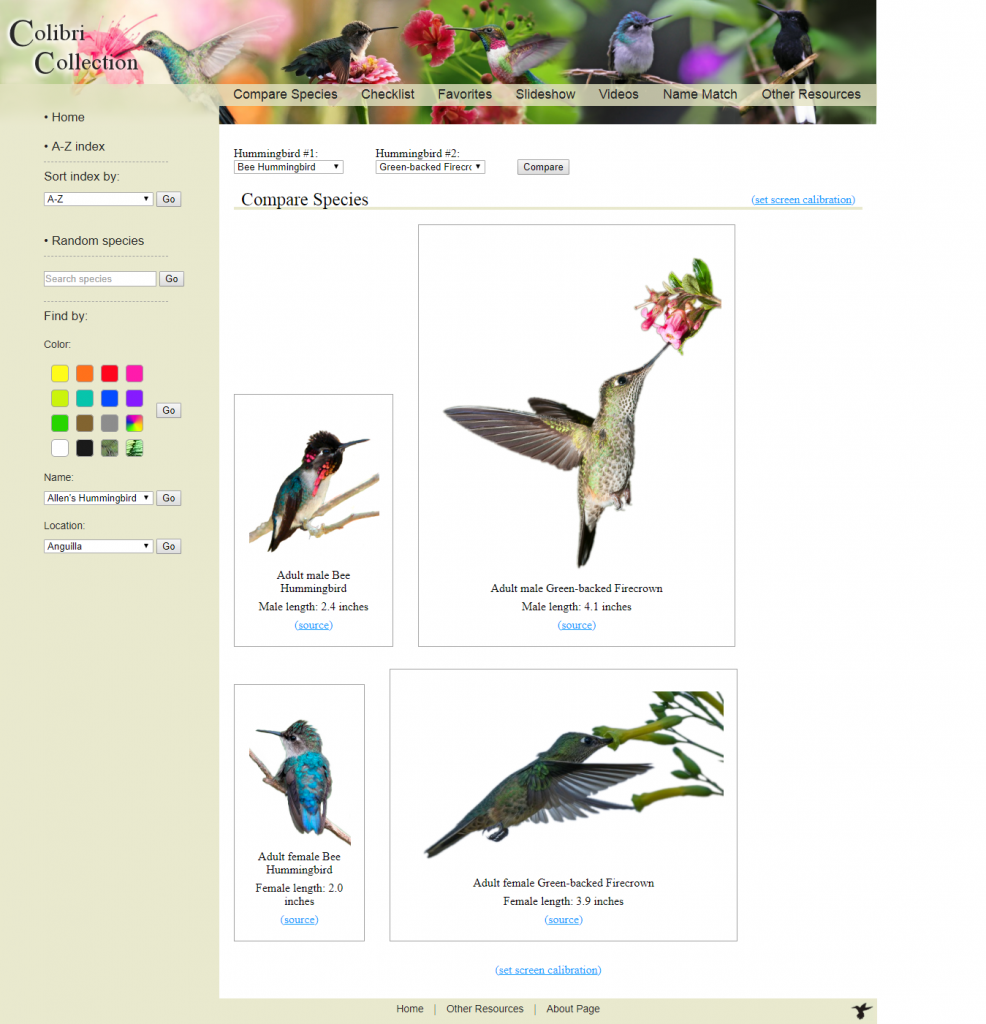
This scaling function was used for the comparison page as well as individual hummingbird wiki pages.
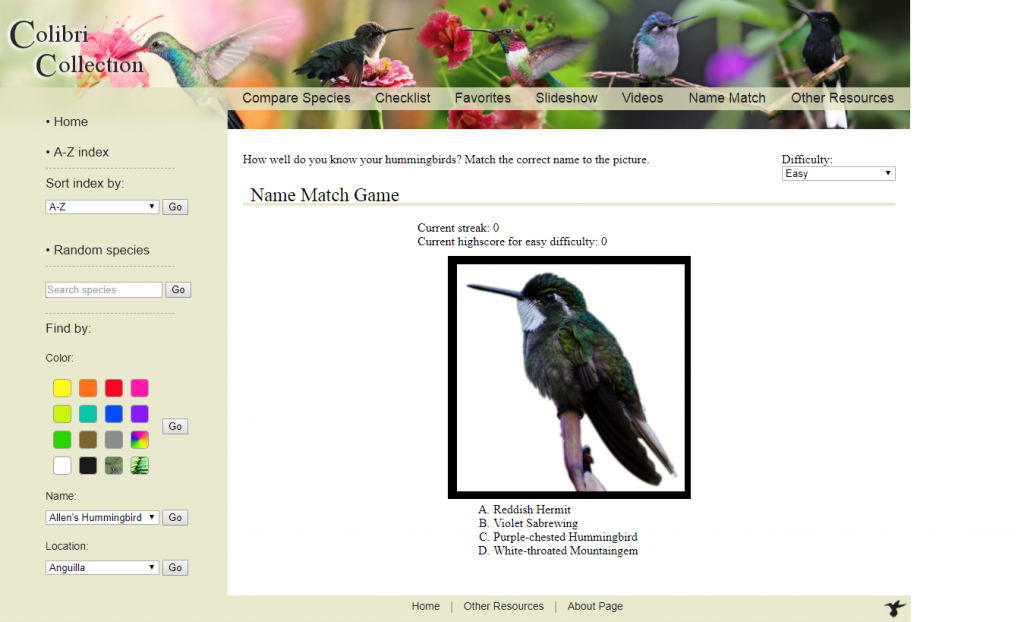
Other features included a name-matching game that dynamically generated sets of hummingbird pictures.
The sets were generated with different database query logic for each difficulty level of the game. Easy level had a more random query which ensured closely related birds were not chosen, leading to easier matching attempts. Harder levels choose more closely related hummingbirds based on the genus of the bird.
JavaScript/jQuery was used to check the answers and change elements on the page based on the outcome.
Scores for each difficulty level were stored in the database per user to allow highscores.
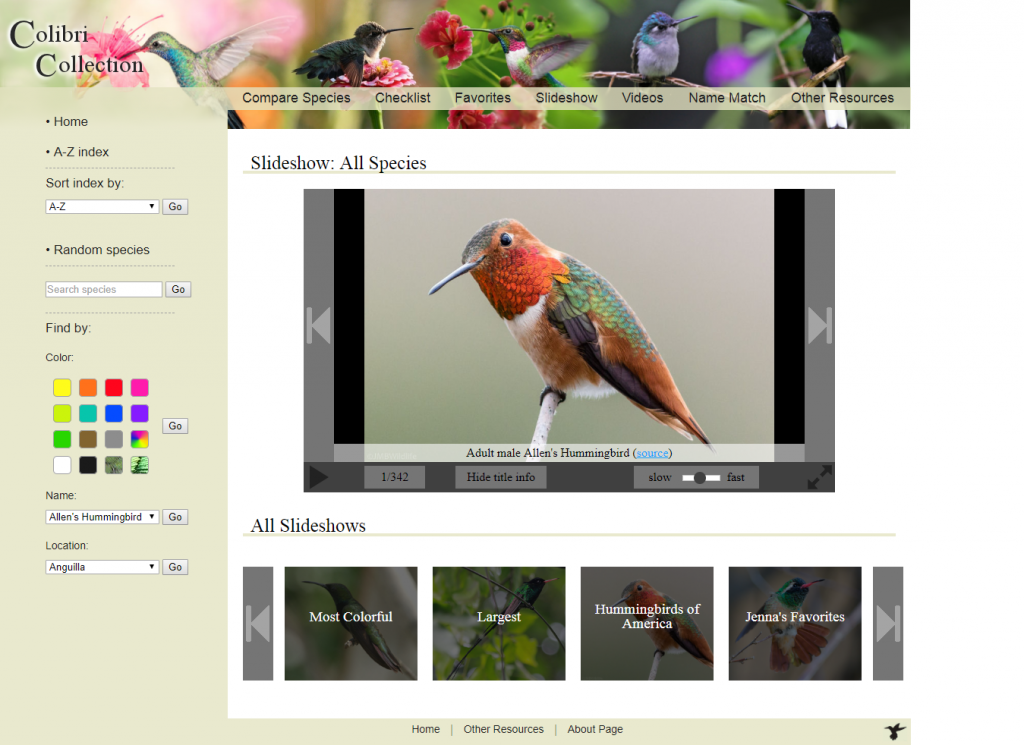
A custom slideshow was also coded. This included an automatic tracking of the user’s hummingbirds they added to their favorite’s list and created a slideshow with the list.
The front-end of the slideshow used JavaScript/jQuery for smooth transitions between photos, updating the slide number, an option to show or hide title information of the current slide, and a speed toggle along with forward and backward buttons.
On the sidebar you can find additional functions for sorting hummingbirds by color or location. Each hummingbird was tagged with various colors in their plumage and any location they could naturally be found in.
Database queries for any combination of these and other queries on the site were cached using Memcache and cleared upon certain changes or on an expiration time.
Certain content for the hummingbird bio pages was gathered through Google using a web scraper coded in Python.